The Mission
UnaMentis needed high-quality text-to-speech that could run entirely on-device, with zero network latency and complete privacy. When Kyutai released Pocket TTS in January 2026, it was exactly what we were looking for: a 100M parameter neural TTS model that delivers natural, expressive voices while running on CPU alone.
There was just one problem: there was no iOS implementation.
The official Kyutai Pocket release included Python/PyTorch code for inference. It worked beautifully on servers and desktops. But iOS apps cannot run PyTorch. To bring Pocket TTS to UnaMentis, we would need to port the entire model to a framework that could run natively on Apple devices.
Why This Mattered
Until Pocket TTS, on-device TTS meant choosing between robotic system voices (Apple's AVSpeechSynthesizer) or multi-gigabyte neural models requiring specialized hardware acceleration. Kyutai Pocket breaks this tradeoff entirely: neural quality at ~100MB, running on any iPhone's CPU.
The Story at a Glance
This infographic captures the entire porting journey. Read on for the full details.
Click to view full size
The goal was not just "working" audio. It was near-identical waveform output (correlation > 0.95) compared to the Python reference. Why such a high bar? Because close is not good enough. A model that produces different audio might sound acceptable, but it could exhibit edge-case failures, mispronunciations, or artifacts that the original does not. True fidelity means the Rust port can be trusted as a drop-in replacement.
The Challenge
Porting an ML model between frameworks sounds straightforward: translate the architecture, load the weights, run inference. In practice, it is treacherous:
Numerical Precision
PyTorch and Candle (our Rust ML framework) do not compute matrix multiplications in the same order. Floating-point addition is not associative. Tiny errors accumulate across 6 transformer layers, 6 residual blocks, and temporal upsampling, until the output is unrecognizable.
Implicit Conventions
Does RoPE use interleaved or split-half format? Does LayerNorm use epsilon 1e-5 or 1e-6? Is the activation ELU or GELU? These are not always documented. They are discovered by comparing bytes.
Architecture Gaps
The reference implementation works, but why it works requires reverse-engineering. Voice conditioning concatenates embeddings in a specific order. The FlowNet averages two time embeddings for Lagrangian Self-Distillation. None of this is obvious from reading code.
Model Complexity
Pocket TTS combines FlowLM (~70M params), an MLP consistency sampler (~10M params), and Mimi VAE decoder (~20M params). Each component has its own streaming state, KV caches, and architectural quirks.
To combat this, we invested heavily in documenting the Python reference implementation itself. We created comprehensive documentation extracted directly from the Python source, including streaming convolution algorithms, state management patterns, and layer-by-layer architecture details. This "source-of-truth" documentation became essential. When stuck, the answer was usually already documented locally.
Multi-Agent AI Collaboration
Rather than a single Claude session grinding through an endless debugging marathon, this project employs a multi-agent collaboration pattern with five distinct roles. This architecture evolved during the project, starting with three agents and expanding to five as new needs emerged.
Why Multiple Agents?
Fresh eyes matter. A new Claude session with no prior context often spots what hours of debugging missed. By design, our auxiliary agents are invoked as fresh sessions. This is not a limitation. It is a feature.
The Five Agents
Implementation Agent
Primary Worker
The workhorse that lives in the code. It writes Rust, runs tests, adds debug instrumentation, and compares tensor values. It maintains a running log of discoveries in a tracking document, documenting what has been tried, what has been fixed, and what still diverges.
The implementation agent is allowed to be messy. It leaves debug statements everywhere, creates temporary Python scripts, modifies test outputs. When hunting for a 5th-decimal-place discrepancy, you need instrumentation, not cleanliness.
Cleanup Auditor
Fresh Eyes Review
A fresh Claude session invoked periodically to survey the damage. The Cleanup Auditor reads the codebase with no prior context and catalogs debug statements, unused imports, dead code, temporary files, and documentation drift.
Critically, the Cleanup Auditor does not fix anything. It produces a structured report that humans review. This separation prevents premature cleanup while ensuring nothing is forgotten.
Research Advisor
External Research
When truly stuck, a separate Claude session researches external sources: Kyutai's official docs, reference implementations, Candle GitHub issues, academic papers. It provides structured suggestions ranked by confidence level.
The Research Advisor does not touch code. It produces a briefing with hypotheses to test, approaches to try, and links to relevant resources.
Verification Agent
Generator-Critic
Added to close the feedback loop between code changes and numerical accuracy. After the Implementation Agent makes changes, the Verification Agent builds the Rust binary, runs the test harness, compares against Python reference, and reports metrics with deltas.
This is the "Critic" in a Generator-Critic pattern. It catches regressions immediately and provides quantitative feedback: "Correlation improved from 0.01 to 0.013."
Progress Tracker
Morale & Planning
A weekly dashboard agent that aggregates metrics over time: correlation history, issues fixed vs remaining, velocity, and time-to-target estimates.
When you have been debugging for weeks, seeing "14 issues fixed, correlation improved 8x from initial" provides motivation and demonstrates progress.
Communication Through Artifacts
All agents communicate through artifacts, not real-time chat. Each agent produces a structured report. The implementation agent reads these reports to inform its work. This async collaboration pattern allows:
- Parallel investigation streams
- Fresh perspectives without context contamination
- An audit trail of decisions and suggestions
The Validation Framework
How do you know if a port is correct? This project developed a three-layer validation approach:
Layer 1: Numerical Accuracy
Compare tensors directly with strict thresholds:
Internal representations should be nearly identical
Final output should strongly correlate
These thresholds are strict. A 0.90 correlation might sound fine but could hide systematic errors.
Layer 2: Intelligibility (ASR Round-Trip)
Run both Python and Rust outputs through Whisper speech-to-text. Compare Word Error Rates. If Rust produces 5% more transcription errors than Python, something is wrong, even if the waveforms look plausible.
This catches bugs that numerical metrics miss: audio that is internally consistent but semantically degraded.
Layer 3: Signal Health
Sanity checks on the output:
- No NaN or Inf values
- Amplitude in audible range (0.01-1.0)
- DC offset < 0.05
- RMS level computed and logged
These catch catastrophic failures early.
The Debugging Journey
Where We Started
The first Rust synthesis attempt produced correlation 0.0016. Essentially random noise relative to the Python reference. Sample counts were wrong. Amplitudes were off by 10x. Something was fundamentally broken.
The Discovery Process
Rather than guessing, the approach was systematic: compare intermediate tensors, layer by layer, until divergence is found. This required building comparison infrastructure:
validation/dump_intermediates.py: Export Python tensors at each layertest-tts --export-latents: Export Rust tensors in numpy formatvalidation/compare_intermediates.py: Compute cosine similarity, RMSE, max error
The 14 Issues Fixed
Methodically, issue by issue:
| # | Issue | Discovery Method |
|---|---|---|
| 1 | Tokenization format: Rust produced 32 tokens, Python produced 17 | Token count comparison |
| 2 | RoPE format: Rust used split halves, Python uses interleaved pairs | Query vector comparison after RoPE |
| 3 | LayerNorm vs RMSNorm: Model weights have bias terms which RMSNorm ignores | Weight shape inspection |
| 4 | FlowNet sinusoidal embedding order | Intermediate tensor comparison |
| 5 | MLP activation function: SiLU not GELU | Activation output comparison |
| 6 | AdaLN chunk ordering | Layer output comparison |
| 7 | LSD time progression averaging | Research Advisor identified from paper |
| 8 | SEANet activation: ELU not GELU | Decoder output comparison |
| 9 | Voice conditioning concatenation: Rust added, Python concatenates | Conditioning tensor comparison |
| 10 | Voice conditioning sequence ordering: Voice first, then text | Python source reading |
| 11 | FinalLayer missing normalization | Layer output comparison |
| 12 | SEANet output activation: Removed spurious tanh | Amplitude analysis |
| 13 | FlowNet TimeEmbedding RMSNorm | Intermediate tensor comparison |
| 14 | Latent denormalization location | Pipeline flow analysis |
Each fix was documented with the problem, the solution, how it was verified, and the quantitative impact (before/after metrics).
Techniques That Worked
Immutable Tracking Document
PORTING_STATUS.md is the single source of truth. Every fix gets documented with what the problem was, what the solution was, how it was verified, and quantitative impact. This prevents re-discovering the same issue and enables handoff.
Fresh-Eyes Rotation
Auxiliary agents are designed for fresh Claude sessions with no prior context. Fresh eyes notice things that a fatigued agent misses. The prompts are stored in version control for reproducibility.
Confidence-Graded Suggestions
The Research Advisor categorizes suggestions as High Confidence (backed by documentation), Worth Trying (reasonable hypotheses), or Speculative (long shots). This prevents treating every idea equally.
Hypothesis-Driven Debugging
Each debugging session has explicit hypotheses: "KV cache values from voice phase may be incorrect." When a hypothesis is ruled out, it is documented, preventing future agents from testing it again.
Generator-Critic Pattern
After the Implementation Agent generates code changes (Generator), the Verification Agent validates them (Critic). This catches regressions immediately and provides quantitative progress tracking.
Quantitative Everything
Every debugging session produces numbers: cosine similarity, waveform correlation, sample counts, amplitudes, deltas from previous runs. "It's still wrong" is not actionable. "Correlation improved from 0.0016 to 0.01" is progress.
Document the Reference
Rather than repeatedly diving into undocumented Python source, we created comprehensive documentation of how the reference actually works. This investment paid dividends throughout the project.
Parallel Investigation
Multiple agents can work simultaneously on different concerns. They communicate through artifacts (reports, documents), not real-time chat. This is async collaboration at its best.
Results & Release
On January 24, 2026, the project achieved its first public release milestone: Pocket TTS iOS v0.4.0 (Beta).
The Journey in Numbers
First attempt: essentially random noise
Short phrases: nearly identical to Python
Through systematic debugging
Each documented with before/after
Milestone Timeline
| Milestone | Correlation | Date |
|---|---|---|
| Initial attempt | 0.0016 | January 2026 |
| After 14 architectural fixes | 0.013 | January 2026 |
| With streaming Mimi decoder | 0.64 | January 2026 |
| With replicate padding | 0.81 | January 2026 |
| v0.4.0 Beta Release | 0.81 | January 24, 2026 |
What's Included in v0.4.0
- Complete TTS pipeline: FlowLM transformer (~70M params), MLP consistency sampler (~10M params), Mimi VAE decoder (~20M params)
- 8 built-in voices: Alba, Marius, Javert, Jean, Fantine, Cosette, Eponine, Azelma
- iOS XCFramework: Universal binary for device (arm64) and simulator (arm64-sim)
- Swift bindings: UniFFI-generated bindings with high-level async/await wrapper
- Streaming synthesis: Overlap-add implementation for low-latency playback
Current Capabilities
| Phrase Type | Correlation | Status |
|---|---|---|
| Short (~17 tokens) | 0.81 | Excellent |
| Medium (~50 tokens) | Working | Intelligible |
| Long (~100+ tokens) | Working | Up to ~25 seconds |
iOS Demo App
To validate the Rust port and demonstrate the iOS integration, we built a complete demo application that showcases Pocket TTS running natively on iPhone. This app served as both a testing harness during development and proof that the entire pipeline works end-to-end on real iOS hardware.
Real Device, Real Performance
The demo app runs entirely on-device with no network calls. Text-to-speech synthesis happens locally on the iPhone's CPU, demonstrating that high-quality neural TTS is achievable without specialized hardware acceleration or cloud services.
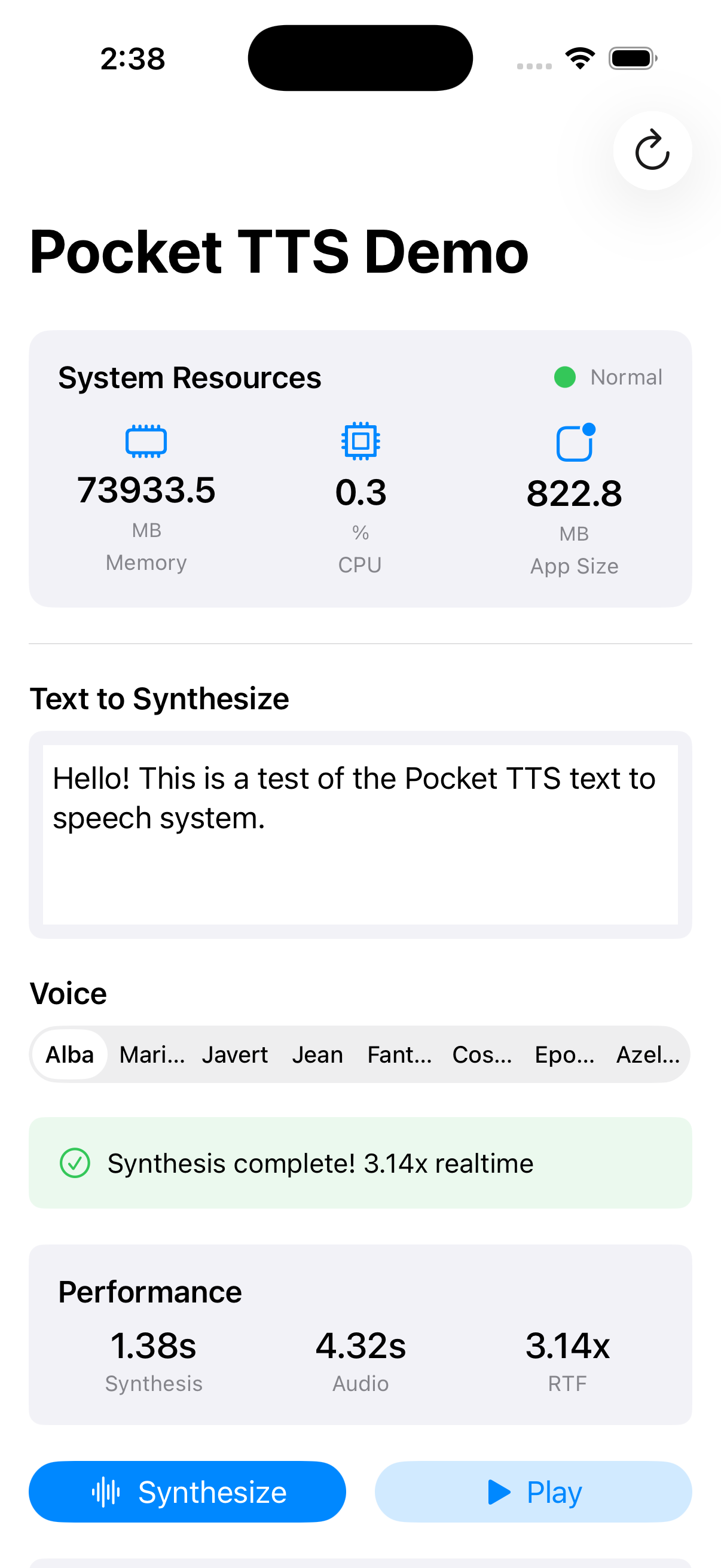
The Pocket TTS iOS demo app running on iPhone. Click to view full size.
Demo App Features
- Voice selection: Choose from 8 built-in voices (Alba, Marius, Javert, Jean, Fantine, Cosette, Eponine, Azelma)
- Text input: Type any text and hear it synthesized in real-time
- Streaming playback: Audio plays back with low latency using overlap-add synthesis
- Native SwiftUI: Clean, responsive interface built with modern Apple frameworks
- Performance metrics: Debug view shows synthesis timing and audio statistics
The demo app uses the same Swift bindings and XCFramework that will power UnaMentis. It validates that the integration works correctly and provides a reference implementation for other developers who want to integrate Pocket TTS into their own iOS applications.
Open Source Project
pocket-tts-ios
The entire Rust/Candle implementation is open source under the MIT license. The project includes the complete inference engine, pre-built iOS XCFramework, Swift bindings, validation harness, and all documentation.
Repository Structure
src/- Rust inference engine using Candlebindings/- UniFFI Swift bindingsvalidation/- Python reference comparison harnessdocs/python-reference/- Comprehensive Python implementation documentationdocs/prompts/- Agent orchestration prompts (reusable)docs/audit/- Historical audit reports
Reusable Patterns
Beyond the TTS implementation itself, the project produced reusable artifacts for future ML porting projects:
- Multi-agent orchestration guide: The five-agent architecture with prompts
- Validation framework: Three-layer approach (numerical, intelligibility, signal health)
- Tracking document template: Structure for systematic debugging documentation
- Quality infrastructure: Pre-commit hooks, CI/CD pipelines, coverage configuration
Lessons Learned
Numerical Equivalence is Hard
Even "simple" operations like matrix multiplication can differ between frameworks. Plan for layer-by-layer comparison from the start.
Fresh Eyes Matter
A new session with no baggage often spots what hours of debugging missed. Build this into your workflow with scheduled agent rotations.
Document Obsessively
The tracking document is not overhead. It is the difference between progress and circles.
Separate Concerns
The agent doing implementation should not also worry about cleanup, research, or metrics. Let each agent focus on one job.
Quantify Everything
"It's still wrong" is not actionable. "Correlation improved from 0.0016 to 0.01" is progress.
Trust the Process
With 14 issues fixed and more to find, the approach is working. Stay systematic.
Evolve the Architecture
The multi-agent pattern started with 3 agents and grew to 5 as new needs emerged. Do not be afraid to add agents when you notice gaps.
Quality Does Not Block Debugging
Set up hooks and CI, but design them to track technical debt rather than prevent it during active development.
The Story Continues
The architecture is verified correct. All latents match Python exactly (cosine similarity = 1.0). The remaining work focuses on EOS detection refinement for longer phrases. The goal of 0.95 correlation is within reach. The infrastructure is in place. The methodology is proven.